
The Hitchhiker's Guide to Deep Learning: Python and JS examples.
Deep Learning : Pytorch and Tensorflow.js Examples

For a hitchhiker, details come later. Right now, I just need the what, why, and where, in plain words.
Take the ReLU function for example.
You could try learning it by staring at the beast below (which might fry your brain if you’ve never seen it):
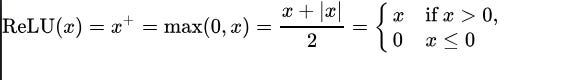
Or the hitchhiker's way:
ReLU is a non-linear function.
And in Deep Learning, non-linear functions are how models learn complex patterns.
So every time you hear non-linear, think: “This is how the model does the thinking.”
And what are linear functions?
They're just the model passing or projecting data using weights, like a pipe system organizing how information flows and combines(affine transform).
So what is Deep Learning?
It’s just building one massive function, a cocktail of linear (structure) and non-linear (complexity) layers, that’s good enough to recognize patterns and make decisions.
Think of Deep Learning as a layered smoothie:
Blender blades (linear layers): chop and mix your ingredients, apples, kale, raw data.
Flavor enhancers (non-linearities): salt, sugar, spices. Small but essential, they turn that chunky mess into something tasty.
The recipe (loss + optimizer): tweaks the quantities until your smoothie consistently tastes right.
The recipe? That’s training, finding the perfect blend.
And now, let’s build one. With TensorFlow.js.
TensorFlow.js (tfjs)
Yep, it’s JavaScript, but with some serious reach.
There are three layers to tfjs:
@tensorflow/tfjs: runs anywhere WASM is supported (browsers, desktop, etc.)@tensorflow/tfjs-node: Node.js with C++ bindings@tensorflow/tfjs-node-gpu: CUDA-accelerated, Node.js GPU flavor (Linux only)
Why tfjs?
Because it's the fastest way to get started—no Python environment setup hell.
Install with:
npm install @tensorflow/tfjs
Or in-browser:
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs"></script>
Building a Neural Network: A Simple Example
Let’s build a tiny binary classifier:
import * as tf from '@tensorflow/tfjs';
// 1. Define the model
const model = tf.sequential();
// Input layer: 3 features → Hidden layer: 16 neurons, ReLU activation
model.add(tf.layers.dense({
inputShape: [3],
units: 16,
activation: 'relu'
}));
// Output: 1 neuron, sigmoid activation for binary classification
model.add(tf.layers.dense({
units: 1,
activation: 'sigmoid'
}));
// 2. Compile the model
model.compile({
optimizer: 'adam',
loss: 'binaryCrossentropy',
metrics: ['accuracy']
});
// 3. Dummy training data
const xs = tf.tensor2d([
[0.2, 0.4, 0.6],
[0.1, 0.3, 0.5],
[0.8, 0.2, 0.1],
[0.9, 0.7, 0.3]
]);
const ys = tf.tensor2d([
[0],
[0],
[1],
[1]
]);
// 4. Train the model
async function trainModel() {
console.log('Training started...');
await model.fit(xs, ys, {
epochs: 20,
callbacks: {
onEpochEnd: (epoch, logs) => {
console.log(`Epoch ${epoch + 1}: Loss = ${logs.loss.toFixed(4)}, Accuracy = ${logs.acc.toFixed(4)}`); // may be logs.accuracy in newer versions
}
}
});
console.log('Training complete. Ready to predict!');
}
trainModel();
// 5. Predict
async function makePrediction() {
const sample = tf.tensor2d([[0.5, 0.5, 0.5]]);
const prediction = model.predict(sample);
prediction.print();
}
setTimeout(makePrediction, 3000);
Breaking It Down:
Model Definition:
tf.sequential()builds our smoothie blender. The hidden layer uses ReLU for flavor, capturing complex, nonlinear features.Compilation:
adamoptimizer +binaryCrossentropyloss = a recipe for binary classification.Training:
We train over 20 epochs using dummy data. In real life, you'd use bigger data and fine-tune the knobs.Prediction:
Once trained, we feed in new data and get a prediction between 0 and 1, probability style.
This is the core idea:
Deep Learning = Smoothie Engineering.
Training = the journey from raw ingredients to something actually edible.
Wild part?
With just this intuition, this code will translate beautifully to Python/PyTorch.
PyTorch Deep Learning Model
If you got the intuition (and survived the JS example), this one should click instantly.
Minimal explanation, let the code do the talking.
import torch
import torch.nn as nn
import torch.optim as optim
# 1. Define the neural network model
class CClassifier(nn.Module):
def __init__(self):
super(CClassifier, self).__init__()
self.net = nn.Sequential(
nn.Linear(3, 16), # Input layer: 3 features → Hidden layer: 16 neurons
nn.ReLU(), # Non-linear activation
nn.Linear(16, 1), # Output: 1 neuron for binary classification
nn.Sigmoid() # Output squashed between 0 and 1
)
def forward(self, x):
return self.net(x)
# 2. Instantiate the model
model = CClassifier()
# 3. Define loss and optimizer
criterion = nn.BCELoss() # Binary Cross-Entropy Loss
optimizer = optim.Adam(model.parameters(), lr=0.01)
# 4. Training data
x_data = torch.tensor([
[0.2, 0.4, 0.6],
[0.1, 0.3, 0.5],
[0.8, 0.2, 0.1],
[0.9, 0.7, 0.3]
], dtype=torch.float32)
y_data = torch.tensor([
[0.0],
[0.0],
[1.0],
[1.0]
], dtype=torch.float32)
# 5. Train the model
num_epochs = 20
print("Training started...\n")
for epoch in range(num_epochs):
optimizer.zero_grad()
outputs = model(x_data)
loss = criterion(outputs, y_data)
loss.backward()
optimizer.step()
print(f"Epoch {epoch+1:02d}/{num_epochs} - Loss: {loss.item():.4f}")
print("\nTraining complete. Ready to predict!\n")
# 6. Make a prediction
sample = torch.tensor([[0.5, 0.5, 0.5]], dtype=torch.float32)
prediction = model(sample)
print("Prediction for [0.5, 0.5, 0.5]:", prediction.item())
If you read the comments closely, you’ll notice:
We're just building that one big function, a blend of linear and non-linear layers.
Same smoothie, different blender (this time, PyTorch).
The only real difference between this and an LLM is the complexity of the function and the type of problem.
This is binary classification. An LLM? Language modeling with billions of parameters.
Same fundamental idea, just scaled into the stratosphere.
But the main point stands:
Intuition gets you from zero to one fast.
What you do from there? That’s on you.
And here's the thruth:
In the real world, you’ll rarely build models from scratch(although good to know).
You’ll use transfer learning, pretrained weights, and model hubs.
Unless you’re doing cutting-edge research, skip the scary equations, for now.
You can always circle back when your gut says, “Okay, now I’m ready for the deep end.”
When you’re learning, listen for intuition, not just instruction.
That’s how you hitchhike to mastery.